Korelácie
| Príklad v programe STATISTICA | Príklad v programe UNISTAT |
Čo je korelácia. Korelácia je miera závislosti medzi dvoma alebo viacerými premennými. Premenné musia byť prinajmenšom merané na intervalovej škále, ale sú aj iné typy korelačných koeficientov, ktoré pracujú s ďalšími typmi dát. Korelačný koeficient môže dosahovať hodnoty od -1 do +1. Hodnota -1 reprezentuje najvyššiu negatívnu a +1 najvyššiu pozitívnu koreláciu. Hodnota 0 vypovedá o žiadnej korelácii.
Jednoduchá lineárna korelácia (Pearsonovo r). Najviac používaným typom korelačného koeficienta je Pearsonov, ktorý sa používa, ak premenné sú merané prinajmenšom na intervalovej škále. Korelačný koeficient nezávisí od mierky, v ktorej boli premenné merané. Kľudne môžme korelovať výšku s hmotnosťou, vyjadrené buď v centimetroch a kilogramoch, alebo v palcoch a pondoch. Korelačný koeficient vyjde rovnaký. Korelácia je vysoká, ak sa dá meranými bodmi v rovine metódou najmenších štvorcov "dobre preložiť" priamka. Táto priamka sa nazýva regresná priamka. Metóda najjmenších štvorcov znamená, že súčet umocnených vzdialeností meraných bodov od regresnej priamky je najmenší možný. Tieto vzdialenosti sa nazývajú rezíduá.
Ako interpretovať korelačný koeficient. Korelačný koeficient r reprezentuje lineárnu závislosť medzi dvomi premennými. Ak r umocníme, získame koeficient determinácie, krorý reprezentuje proporciu spoločného rozptylu, teda na koľko percent zmena jednej premennej ovplyvní druhú. Je to informácia o sile relácie medzi premennými a má prinajmenšom taký význam ako informácia o významnosti korelácie.
Významnosť korelácie. Významnosť korelácie je základná informácia o jej reliabilite. (viď úvod). V závislosti na veľkosti vzorky sa významnosť mení. Test významnosti je založený na predpoklade, že rozloženie reziduálnych hodnôt pre závisle premennú y je normálne, a že variabilita týchto hodnôt je rovnaká pre všetky hodnoty nezávisle premennej x. Avšak metóda monte carlo empiricky dokazuje, že dodržanie týchto predpokladov nie je nevyhnutné, ak máme dostatočne veľkú vzorku a odchýlka od normality nie je veľmi veľká. Nie je všeobecné pravidlo, ale veľa výskumníkov považuje n=50 za dosť na to, aby nenastalo skreslenie výsledkov, a pri n=100 už sa nezaujímajú o normalitu údajov. Je to však vždy ohrozenie validity informácie, ktorú korelačný koeficient poskytuje.
Vybočujúce merania (outliers). Vybočujúce merania sú atypické, málo sa vyskytujúce merania. Pretože sa regresná priamka vypočítava metódou najmenších štvorcov, majú vybočujúce body nemalý vplyv na jej sklon. Jeden vybočujúci bod je schopný podstatne zmeniť nielen sklon regresnej priamky, ale aj samotný korelačný koeficient, ako je ukázané na nasledujúcom obrázku. Korelácia s vybočujúcim bodom je tu vysoká, bez neho je blízka nule. Samozrejme, nikdy preto nepodložíme záver len výpočtom, vždy urobíme aj vizuálnu kontrolu korelogramu.
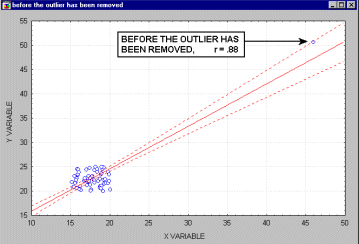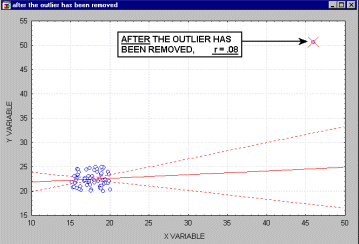
Ak je vzorka relatívne malá, vylúčenie každého bodu, ktorý nie je čistý vybočujúci bod, má za následok silný vplyv na regresnú priamku aj samotný korelačný koeficient. Ako vidieť na nasledujúcom obrázku,niekedy je ťažko určiť, či sa jedná o vybočujúce body, alebo iba o extrémne hodnoty.
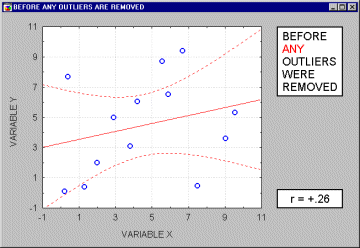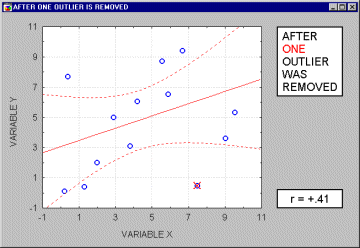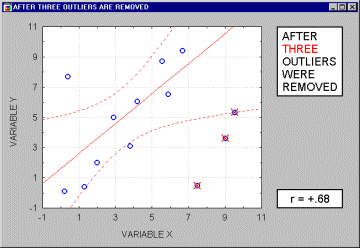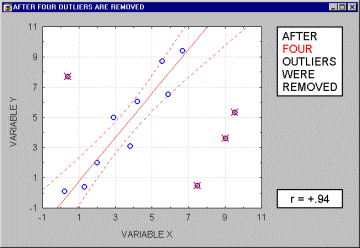
Poväčšine veríme tomu, že vybočujúce merania reprezentujú náhodnú chybu, ktorú máme pod kontrolou. Žiaľ, neexistije široko akceptovateľná metóda automatického odstránenia vybočujúcich hodnôt. A nemusia mať len za následok nárast korelačného koeficienta, ale aj pokles pod úroveň "akceptovateľnej" korelácie.
Kvantitatívny prístup k vybočujúcim bodom. Niektorí výskumníci vylučujú body, ktoré sú mimo intervalu ± 2x smerodajná odchýlka od priemeru. Pre niektoré oblasti výskumu je takéto čistenie dát nevyhnutné. Napríklad v kognitívnej psychológii pri skúmaní reakčného času. Prístup k dátam z hľadiska identifikácie vybočujúcich meraní je individuálny, výskumník musí zvážiť sám, aké sú akceptovateľné praktiky v oblasti jeho výskumu. Vybočujúci bod nemusí znamenať len chybne prevedené meranie. Niekedy práve vybočujúce merania nás upozorňujú na výskyt fenoménu kvalitatívne odlišného od typickej schémy pozorovanej vo výbere.
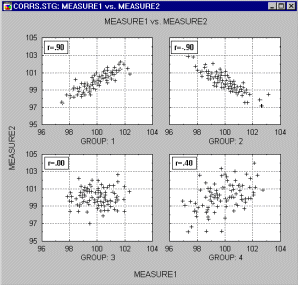
Korelácia v nehomogénnych skupinách. Nedostatok homogenity vo vzorke, ktorá je predmetom výskumu, tiež posúva hodnotu korelácie. Predstavme si, že vypočítame koreláciu z dát pochádzajúcich z dvoch rôznych skupín, ako je to na nasledujúcom obrázku.
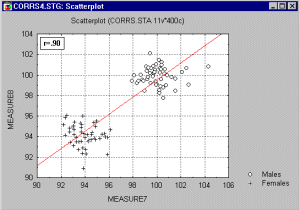
Získali sme vysokú koreláciu, ale keď podrobíme skúmaniu každú skupinu zvlášť, získame korelácie prakticky rovné 0.
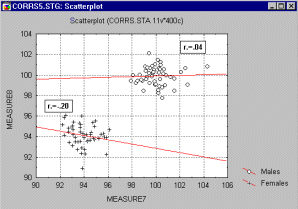
Ak je z korelogramu zrejmé, že máme do činenia s nehomogenitou, a nevieme dve skupiny identifikovať, použijeme prieskumové multivariačné techniky (napr. Cluster Analysis).
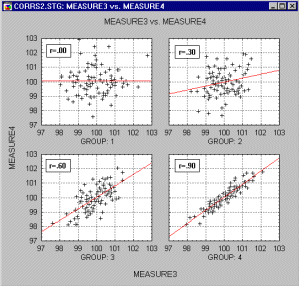
Nelineárny vzťah medzi premennými. Ďalším potenciálnym zdrojom problémov je nelineárny vzťah medzi premennými. Pearsonovo r meria iba lineárny vzťah iba medzi premennými. Nelinearita má za následok nárast súčtu štvorcov vzdialeností od regresnej priamky, aj keď numericky dokazuje významnú závislosť. Možnosť nelinearity je ďalším závažným dôvodom, pre ktorý vizuálne kontrolujeme korelogram pred ohodnotením korelácie. Napr., nasledujúci graf ukazuje silnú koreláciu medzi premennými, ktorá je zle popísaná priamkou.
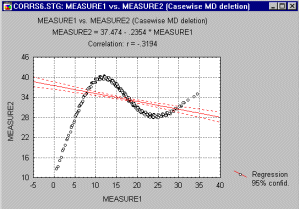
Meranie nelineárnej závislosti. V prípade, že vzťah medzi premennými nie je lineárny, nie je také jednoduché, ako Pearsonovo r, ho popísať. Keď je krivka monotónna, rastúca alebo klesajúca, mohli by sme skúsiť transformovať jednu, alebo obe premenné napr. použitím logaritmickej funkcie a na nové dáta aplikovať pearsonovu koreláciu. Iná možnosť je použiť iný korelačný koeficient z neparametrických metód, napr. Spearmanov, ktorá pracuje len s poradím nameraných údajov. Avšak táto korelácia je menej senzitívna a niekedy neprodukuje žiaden výsledok. Najprecíznejšia metóda je neľahká a požaduje experimentovanie s dátami. Je treba buď pokúsiť sa sami identifikovať funkciu a použite techniku "goodness-of-fit" na jej otestovanie, alebo rozdeliť jednu premennú na viacero podskupín, tým sa vytvorí takzvaná grouping premenná, do ktorej je treba dať pre každého respondenta číslo skupiny, do ktorej patrí, a následne použiť analýzu rozptylu (analysis of variance).
Korelačná matica. Prvým krokom analyzovania veľkého množstva dát, ktoré sú obsiahnuté vo väčšom množstve premenných, je vygenerovanie korelačnej matice a preverenie takto objavených, viac či menej očakávaných významných vzťahov. Ako je známe z úvodu, hladina významnosti 0,05 znamená možnosť 5% chyby pri vyslovení úsudku o existujúcej závislosti. Preto treba každú významnú závislosť preveriť, či je "v zhode" s ďalšími výsledkami. Najlepším, i keď drahým riešením odstránenia podozrivých závislostí je výber novej vzorky. Týmto problémom sa hlbšie zaoberá "post-hoc comparations of means" a "breakdown" voľba.
Práca s chýbajúcimi meraniami. Otvára sa otázka, čo robiť v prípade, ak je predmetom výskumu viacero premenných a u niektorých respondentov niektoré meranie nebolo uskutočnené. Ide o takzvané chýbajúce meranie (missing data). Exaktné je vtedy ignorovať všetky ostatné merania daného respondenta (casevise deletion), aby všetky korelácie mohli byť urobené na rovnakej vzorke údajov. Avšak, ak sa chýbajúce merania vyskytujú často a nepravidelne krížom cez všetky premenné, ľahko by sa mohlo stať, že po prísnom vyselektovaní neostanú žiadne dáta. Vtedy ignorujeme chýbajúce merania pre každú dvojicu vektorov osobitne, teda len tie, ktoré sa týkajú tej dvojice vektorov (pairvise deletion). Vo väčšine situácií nie je na tejto metóde nič zlé, zvlášť, keď je chýbajúcich meraní menej ako 10% a sú relatívne náhodne rozložené cez premenné a respondentov (ináč: prípady, cases). Avšak dôsledkom skrytého systematického rozloženia chýbajúcich dát môže nastať systematický posuv výsledkov. Vznikajú rôzne korelačné koeficienty v tej istej korelačnej matici použitím rôznych podmnožín dát práve metódou "pairvise deleting". Problém môže nastať, keď tieto dáta chceme použiť na ďalšiu anlýzu (napr. mnohonásobná regresia, faktorová analýza, clustrová analýza). Preto pri odstráňovaní chýbajúcich meraní po pároch sa musíme presvedčiť, či chýbajúce merania nevytvárajú v dátovej matici nejakú systematičnosť.
Ako identifikovať posuv výsledkov spôsobený párovou selekciou chýbajúcich meraní. K tomuto účelu poslúži popisná štatistika. Ak máme napr. premenné A, B, C, a po párovom vylúčení chýbajúcich meraní v páre A-B nám premenná A dá oveľa menší priemer, resp. štandardnú odchýlku ako po vylučovaní v páre A-B, tak vtedy môžme povedať, že korelácie A-B a A-C boli vypočítané na dvoch rôznych podmnožinách dát, a teda získali sme posuv výsledkov spôsobený nenáhodným rozložením chýbajúcich meraní. Existuje nie veľmi dokonalý spôsob, ako sa s tým vyrovnať. Náhrada chýbajúcich meraní v každom vektore hodnotou priemeru za tento vektor. Tento spôsob produkuje "vnútorne konzistenčnú" množinu výsledkov, má však nevýhodu. Dosadením priemeru za chýbajúce merania sa zmenšuje štandardná odchýlka premennej v závislosti od počtu dosadení, a aj podstatne mení hodnoty korelačných koeficientov.
Falošná korelácia. Je to preukázaná korelačná závislosť medzi dvoma premennými, ktorá vznikla vplyvom ďalšej, ktorú sme opomenuli. Je tu napríklad závislosť medzi počtom nasadených požiarnikov a škodami, ktoré spôsobil požiar. Nemôžme sa uspokojiť s výsledkom, že čím menej je k požiaru zavolaných požiarnikov, tým nižšie sú straty. Opomenuli sme dôležitú premennú, ktorou je rozsah požiaru. Ak teda uvažujeme iba požiare konštantného rozsahu, korelácia sa môže zmeniť dokonca v opačnú. Problém je, ak nevieme odhaliť skrytú premennú. Ak však vieme, môžme použiť aj parciálnu koreláciu na výpočet vzťahu medzi dvoma premennými s eliminovaním vplyvu známej tretej premennej.
Aditivita. Korelačný koeficient nemá vlastnosť aditivity. To znamená, že priemer z korelačných kooeficientov z niekoľkých výberov nie je priemerným korelačným koeficientom všetkých týchto výberov. Pre tento účel je treba korelačné koeficienty transformovať na aditívnu mieru. Koeficient determinácie, alebo takzvaná Fisherova z-hodnota, už vlastnosť aditivity má.
Preložené z:
StatSoft, Inc. (1999). Electronic Statistics
Textbook. Tulsa, OK: StatSoft. WEB: http://www.statsoft.com/textbook/stathome.html
| Príklad v programe STATISTICA | Príklad v programe UNISTAT |